|
Hi all. Recently I read Paul Smaldino’s essay How to Translate a Verbal Theory into a Formal Model and found it hugely informative. It’s conversational in tone, yet densely packed with useful information for the aspiring academic. The paper is the kind which flows so well that it practically summarizes itself. But let's be honest, this is the internet. We’re here for things that are more conversational and dense than is strictly reasonable. And with Darwin as my witness, that’s what this summary is going to be. Just so we’re all on the same page, I’ve included a brief glossary at the end of this post, which covers the terminology I used most often. Check it out if you find yourself unsure of what precisely some of it means. -------------------------------------------------------------------- I Introduction The human mind is mind-bogglingly complex. Its many-layered cognitive, social, linguistic and behavioral systems make it the most sophisticated system in the universe. But human brains have a notable weakness: They have difficulty understanding human brains. We are not built to understand our own neurological function in the way we intuitively understand how to hold tools or identify social nuance in speech. The structure of the brain’s anatomy bears about as much resemblance to actual human thought as the circuits in my TV do to Breaking Bad. We humans tend to think in metaphor and analogy – like the silly one that ended my last paragraph. Our minds take concepts and turn them into theories about how things work, often by representing them as other mundane concepts that we’re more familiar with. A star is like a big ball of fire, a seed is like a baby plant, a zebra is like a striped horse, a statistics lecture is like physical torture, et cetera. We are adept at simplifying objects and systems down to their most relevant or obvious traits to make them easier for our minds to process. This is a powerful strategy for picking apart the nature of the world. But the catch is that we represent these simplified concepts using language, and language sucks. If you don’t believe me yet, maybe you will after I make you read the word “model” for the 172nd time. In science we want to be as precise as possible. While numbers are quite good at that, words aren’t. As Smaldino puts it, “Consider, for example, that words like ‘perception,’ ‘category,’ ‘identity,’ ‘learning,’ and even ‘response’ are sufficiently ambiguous to allow for a multiplicity of interpretations."  Modeling provides an excellent solution to these problems by virtue of not having them. Like the metaphors that came before them, models have the power to take a concept that's overly complex or unobservable and churn it into something that’s easy to follow. But unlike metaphors, they’re not made of language; they’re made of math (and formal logic, math's weird cousin). So not only do models avoid the pitfalls of language, they also gain the benefits of math. They can be scaled up and down, tweaked, rearranged, expanded, analyzed, integrated, compartmentalized, and tested with (relative) ease. If you want to understand sophisticated systems, modeling is essential. 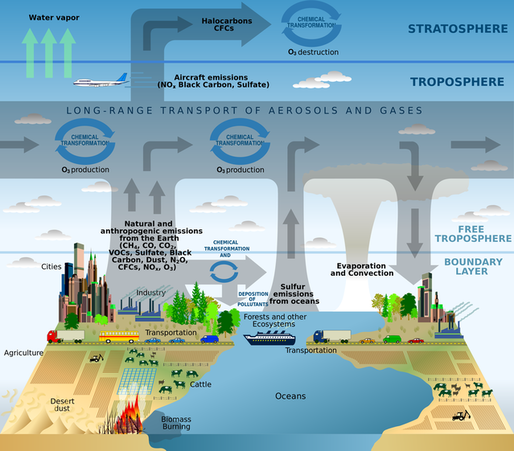 Try imagining this system without the slick infographic. I can’t. (Source) -------------------------------------------------------------------- II Getting Started Learning how to build a model from scratch is not easy. Much like learning to play an instrument, you have to practice, develop many small skills and figure out how to put them all together in concert. And just like learning an instrument, it’s vital to pay attention to what more accomplished players have made. Smaldino writes: “Getting experience with reading, building, and analyzing many different models can provide us with a mental arsenal of parts and ideas that can be used and recombined for novel models.” And as with many things in life, the best way to get started is to steal somebody else’s work. Cover a song! Hop onto a computer, find a good, completed open-source model, and just start messing around with it. You can find plenty of free open-source model code on websites like GitHub and Modeling Commons. NetLogo, a programming language and developing environment for agent-based modeling, also has a substantial library of model code to toy around with. Once you find a model to begin picking apart, start by thinking about how each line of code, every algorithm and function, contributes to the model as a whole. The goal is to understand the connection between the model’s low-level mechanical details and its high-level conceptual fabric. How did the creators choose to represent the model’s states, agents and systems? How are the relationships between these things enacted by the code? How do agents make decisions? Are those decisions a good simulation of how the real thing might behave? Consider the implicit and explicit assumptions made by the model you’ve chosen. These will depend on the type of model you choose to examine, but every model makes assumptions of some kind. Implicit assumptions are those that are made by the model, but are not specifically identified by the model per se. In other words, they are “unspoken assumptions”. Say you've found a model of how sparrows search for food in times of scarcity. It might make the implicit assumption that sparrows want, need, and search for food by flying around using their wings. The model's creators didn’t need to say that kind of thing out loud, as anyone exploring their model will see that this is implied. On the other hand, an explicit assumption is one that you do consciously acknowledge and base the mechanics of your model around. The foraging model might want to be explicit in their assumption of which strategies sparrows might use to forage. For instance, they might assume that sparrows will attempt to maximize the food they gather within 1 mile of their nests, attempting to do so as efficiently as possible and returning home only once they’ve hit a sufficient calorie goal. (Convergent validity: This is also how I order chili cheese fries.)  If that’s not efficient foraging, then I don’t know what is It’s good to think about alternatives to the assumptions a model makes and see if you can work them in on your own. Let’s say the foraging model assumes that sparrows forage in patterns that will maximize their food intake, no matter how long it takes. What happens if you instead assume that their goal is to find the most food in the least time, or by travelling the least distance from their nest? What if they must make frequent returns to the nest to feed and protect their young? What happens to the model if they seek new foraging spots randomly? Does that change the birds’ efficiency? By how much? Do they gradually increase their search area after unsuccessful foraging attempts? All of these can be assumed and incorporated into the model. From there, you can see the effects that these different assumptions had on the outcomes, and compare each new configuration to how things behave in a real-world setting. Getting a feel for how assumptions can shape a model is great practice not just for modeling, but for building concepts and understanding theory in general. Models and theories often exist in symbiosis, a dialogue where refining one pushes the other forward. Try not to focus on either approach exclusively; both are valuable. Smaldino recommends getting experience with tweaking assumptions like this before you tackle your own theories. It’s easier to see the big picture when you’re tweaking somebody else’s design. But when critiquing your own work -- especially work you’re heavily invested in -- it's often difficult to be objective and spot mistakes. So unless we're trying to model how to make mistakes, it's probably for the best that we follow his advice. -------------------------------------------------------------------- III Types of Models There are two major types of models Smaldino identifies: Equation-Based Models, and Computational Models. Smaldino: “Equation-based models involve writing down, well, equations that specify the key relationships between the parts of a system, such as the dynamics of how a population changes.” The power of Equation-Based Models is in their relative simplicity. Because they tend to have few moving parts, they allow you to generate and compare distributions of data on the fly by manually adjusting their parameters. This simplicity also allows them to be more easily understood and communicated. The SIR model of infectious disease spread is a classic (if perhaps all too relevant) example of an Equation-Based Model. As the initialization parameter changes – in this case the effective contact rate – so do the outcome measures – Susceptible individuals (S), Infected individuals (I) and Recovered individuals (R). Hence “SIR”. With an Equation-Based Model, you can plug in different values and quickly see how the dynamics of the system behave in response. Here’s a graphed SIR model predicting COVID infection outcomes. It's designed to demonstrate what happens when you vary the effective contact rate. Note that as the contact rate decreases (as might happen with social distancing), the number of individuals infected at any given time decreases, flattening the curve. 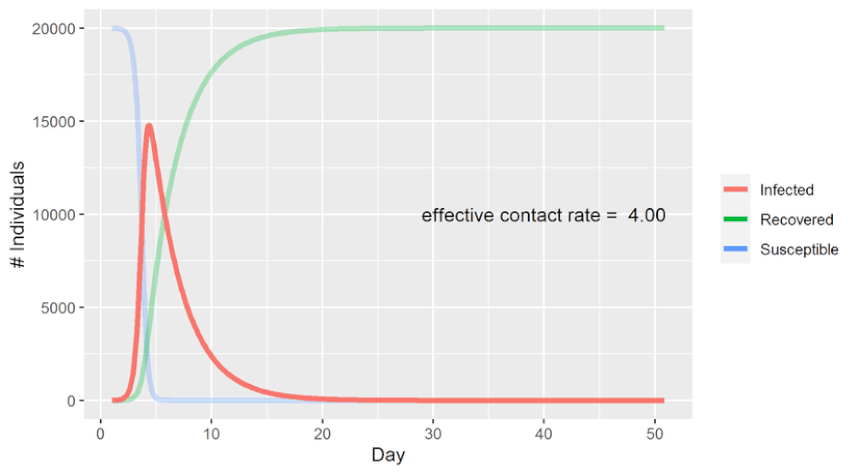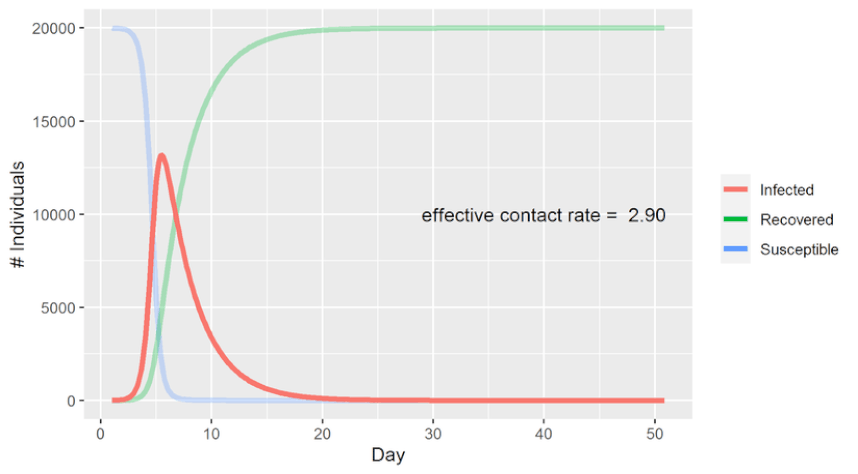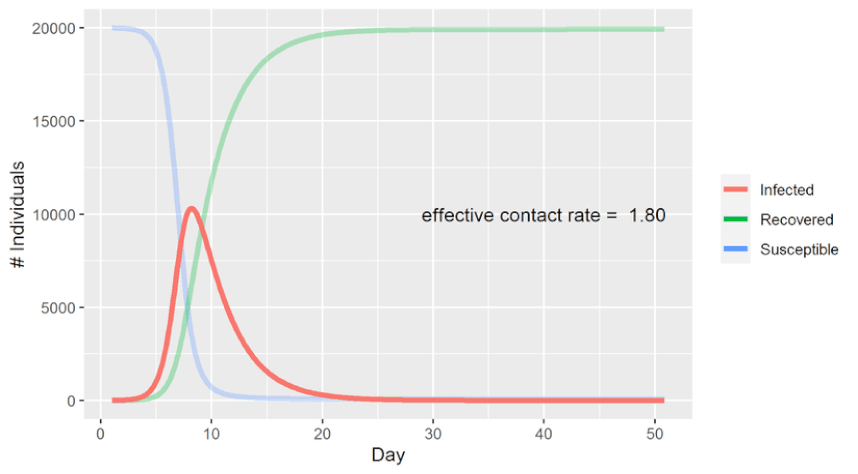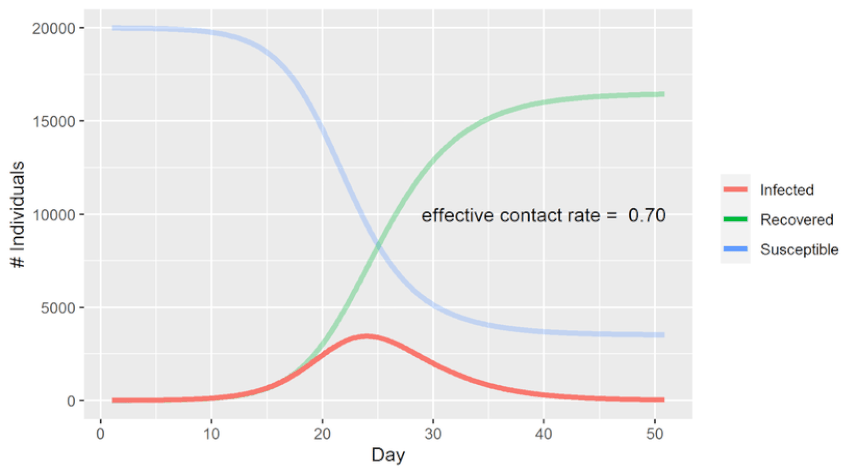 Coming up on America's Next Top Model (Source) So Equation-Based Models are great for straightforward systems with relatively few parameters. But some systems have a huge number of different variables interacting in diffuse, complicated ways. Anyone can run an equation with just a handful of parameters, as with the SIR model. But picture an aerospace engineer trying to model, on paper, all the billions of ways individual air currents might interact with the shape of an airplane’s fuselage. Nobody in their right mind is going to attempt that, and they very well may not be in their right mind by the time they're through. Our engineer would probably learn more about the plane’s aerodynamics by tearing up her paper and tossing the shreds into a wind tunnel. This is where Computational Models come in. Compared to Equation-Based Models, Computational Models allow for modeling far more complex systems with hundreds or thousands of moving parts. Of course, Computational Models still rely heavily on math and equations to drive their simulations. But thankfully, computers eat math and equations for breakfast, so they have the potential to run models with hundreds or thousands of interacting elements at dizzying speeds. They can run your model in 100 different ways before you can recite the first 10 digits of Pi. Agent-Based Models are a common type of computational model in which you create agents with defined properties and behaviors, and then set them free to see what happens. Think of them as cute little robots carrying out their tasks. Agent-Based Models are particularly useful in social science, where we are interested in modeling how humans interact with each other and with the systems that contain them. And since we all know that humans always behave in logical, predictable and totally sane ways, agent modeling is perfect for the job. Here Smaldino references an Agent-Based Model where individual agents are given random walk patterns and the rate of infectious transmission is tracked. The closer an infected agent walks to an uninfected one, the greater the likelihood that the virus jumps to a new host. In this model, a small random walk distance represents a low effective contact rate, whereas a large walk distance represents a high contact rate. Just like before, the low and high contact rate conditions are simulating real-world situations in which social distancing measures are present (low) or absent (high). 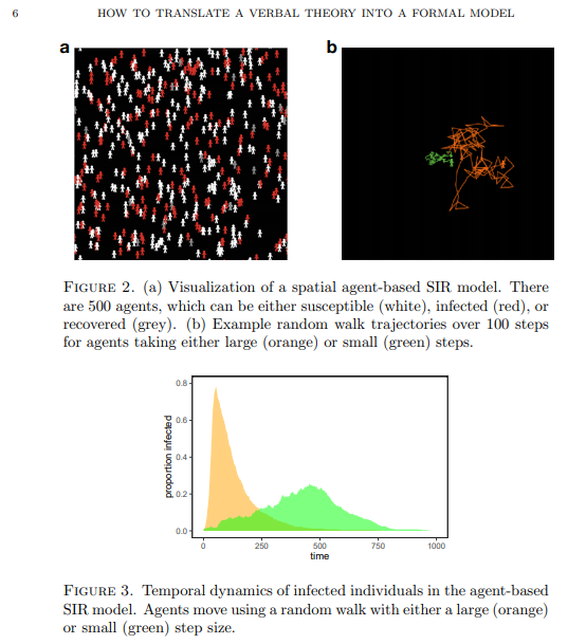 Despite taking an Agent-Based approach and coming from a different source, the infectious curves this model generates are eerily similar to the graphs produced by the Equation-Based Model in the gif shown earlier. Science! Smaldino also makes another distinction between what he calls fine-grained and coarse-grained models. Fine-grained models are those where the input data is precisely measured, as with many models in physics and chemistry. Coarse-grained refers to models primarily using imprecise qualitative data, as with many models in the social sciences. There are a few reasons social sciences rely much more heavily on coarse-grained models: a) The Law of Large Numbers makes it unnecessary to precisely measure every agent’s behavior when their behaviors can be effectively measured in aggregate. b) Many constructs in social sciences, like thoughts, emotions, norms, and intentions, are difficult to operationalize and measure. Even when measurement is possible, our actual ability to do so is often limited by time, resources, ethical constraints, and researcher sanity. c) The sheer, multilayered complexity of many systems studied in social science makes exact assessment of the system’s dynamic interactions virtually impossible. To model systems as complex as those within the human brain is a challenging task. But it’s not impossible! Modeling is perhaps the only way we can begin to understand systems as complex as these. Every scientific view of the mind is a model of some sort. But verbal and unspoken mental models often take the place of documented formal models, and while they can be a helpful starting point, they are not sufficient on their own. They’re just one part of a balanced breakfast. Pretend you’re a college student (if you already are, pretend you’re one who doesn’t have student loan debt). You’re building a verbal theory of how and when people develop romantic attraction to one another. Your theory is off to a good start; it’s intuitive, easy to communicate, and seems to give genuine insight into mating behavior. But until you convert the theory into a formal, testable model, you will never be able to see just how your theorized system would behave in certain conditions. You can speculate, of course, and run simulated models in your head. But at that point you’re simulating a simulation, and that’s both epistemic bad practice and a crime against nature. So let's appease the epistemology gods and learn how to build a proper model. -------------------------------------------------------------------- IV Ten lessons for translating a verbal theory into a formal model 1. Develop relevant skills. You need to study your field or subfield well enough to be able to manipulate its data in useful and informative ways. Gather programming experience in a language of your choice that supports various modeling techniques. [Summarizer note: If you have little or no programming experience, I highly recommend starting with Python. It’s straightforward, has plenty of learning resources available, and supports an enormous range of uses, from data science to giving up.] Smaldino also recommends being well-versed in a variety of theoretical domains: “These include game theory, evolutionary theory, dynamical systems, probability distributions, Bayes’ theorem, network theory, connectionism, and information theory.” Presumably you should be familiar with the kitchen sink too. 2. Be mindful of the literature. The first thing you should do when starting a research endeavor is to read the literature. The second thing is also to read the literature. (The third is to learn to extrapolate from observed patterns in data.) Consulting prior work on the subject helps you to give credit where it’s due and avoid reinventing the wheel by accident. Make sure to be aware of the relevant theoretical and modeling literature in your domain. As always, be interdisciplinary. If you want to model behavioral patterns in response to hormonal changes, but you don’t know what the word ‘pituitary’ means, you might want to hit the books. Having a well-rounded interdisciplinary base of knowledge will allow you to generate more robust models and expand your conceptual toolkit. And it makes you sound smarter. Always nice. 3. Decide on the parts of the system. What are the most important elements of the system you’re trying to model? The essential parts you identify should be determined by the questions you want your model to answer. If your question is “Why do humans attend to status information about other people?”, then your model might be interested in systems of hierarchy navigation, coalitional psychology and reputation management. But if what you want to know is “How do humans process status information,” that’s a different story. Your model might instead focus on proximate factors like shoulder-to-waist ratio, attractiveness, motivational systems, and the brain circuitry responsible for processing and integrating social cues. This design phase may highlight weaknesses in your verbal theories, which serves as another example of how models can improve theory and vice versa. Acknowledge whatever flaws you find and correct them as best as you can. Finally, it is important to consider whether any of the model’s unnecessary elements can be cut without weakening its predictive power. Be a jazz musician; the notes you don’t play are just as important as the ones you do.  Incidentally, sheet music is just a model of music. And music is just a model of math. And math is just a model of everything. (Source) 4. Separate design from construction The hardest part of modeling is designing the damn thing. This is what you should spend the most time on and where you should be the most willing to go back to the drawing board. Once you’ve got the design down, construction is the easy bit. You should have your entire model designed and written out before you start piecing it together. To paraphrase Smaldino, when building a house, you don’t start out by winging it. You develop a complete blueprint first. He recommends this step-by-step process: “[Go] from verbal theory to a set of parts and relationships, to a set of parameters, to a set of analyses, to an algorithmic design in pseudocode, and then finally to a coded model.” 5. Be as simple as you can be, as complicated as you need to be. In a letter, Blaise Pascal once wrote, “I have made this longer than usual because I have not had time to make it shorter.” A similar principle may be applied to the complexity of models. Complex models are often less powerful, but they are also often easier to make! The utility of a model, its reason for existence, is in its ability to boil down a convoluted system to its bare essence. While complexity can be helpful and necessary, it should be incorporated only when it adds something vital that couldn’t be done in a more elegant way. 6. Attack your design. Assail your model’s weaknesses! Seek its flaws! Call it unpleasant names! A model is robust if it can weather the storm of criticism and handle the exceptional as gracefully as the typical. To find out if it can, you need to poke holes in your model until it falls apart, then restructure the weak bits. To do this think of blind spots, scenarios that your model doesn’t seem to properly account for. Feedback from colleagues can help a lot with identifying where these are. Once such scenarios are identified, try running them through the model to see if it produces something useful. If it doesn’t, you have two options. You can either take a step back and think about tweaks that would enable your model to handle these scenarios. Or you can simply accept that they’re outside the scope of your model and intentionally leave them out. Sometimes the latter is for the best. You might find it’s more useful to build a model that does a few things well than one which does many things poorly. It’s also important to critically consider the framework you’re using. Equation-Based and Computational models each have strengths and weaknesses, as do fine-grained and coarse-grained approaches. These variants can often be combined within a single model, if that’s useful. But it’s important to ensure that the framework, design space, assumptions and parameters you have chosen all fit the real-world system you are interested in studying. Using the wrong approach can result in a poor model, and nobody likes those.  Masticatory Calibration Technique 7. Plan your analyses. When considering which analyses you want your model to run, you should first consider the questions you want it to answer. What do you want to know? Which outcome measures are the most relevant, and what analyses are best suited to assess those outcomes? Questions like these will inform your design process, guiding the development of your model until it can produce the information you’re most interested in. Of course, coming up with good questions isn’t always easy. That’s why Smaldino recommends writing out an in-depth, formal description of the model before moving forward with your planned analyses. Having your model laid out on paper ensures you are crystal clear about how it’s supposed to work, that you can easily communicate this to others, and that you have a record of your prior intentions and designs in case something gets changed later. Plus it’s nerdy as hell, and we’re all about that. When it comes to deciding which analyses to conduct, you should always consider what your outcome measures are going to look like. Think about it – you can’t decide whether to use the stovetop or the deep fryer until you’ve decided whether you want soup or chicken wings. Knowing your outputs is especially important with computational models. Since they can handle more complexity, computational models naturally encourage the use of more parameters and initialization conditions. But as the number of parameters grows, the number of possible combinations grows exponentially. You need to be sure that each parameter is justified, and that your outcome measures will represent this permutation space in a useful way. Being aware of all these details ahead of time lets you narrow down the analyses you’ll run on the final outputs. 8. Rethink statistics. Here Smaldino launches into a critique of blindly using inferential statistics to interpret model outputs. Caveat lector: I’m no statistician, so I encourage you to consult the original paper on this section. But I’ll do my best to summarize anyway, because if you've gotten this far then bad summaries are obviously your thing. Smaldino begins by discussing a tendency he has seen with models designed to simulate phenomena. He says that most people educated as behavioral and social scientists will be tempted, mistakenly, to employ inferential statistics like regression analyses to determine how the model’s outputs can be attributed to its inputs. But inferential statistics work by constructing a model of your data generation process, and that’s not necessary if your data were generated by a model to begin with. As Smaldino says (in my favorite sentence of the paper), “There’s no reason to model your model with a shittier model.” You don’t need to infer what the model’s output distributions would look like with a metric boatload of data; just keep running simulations until you’ve generated precisely one boatload. While he does not say this explicitly, the title of this section seems to indicate that he meant this to be a general principle, rather than a specific example. I believe the lesson here is to be mindful of the stats techniques you employ. Don't just autopilot to what you’ve been taught, especially when your model itself could do the same thing without the need for statistical inference. Run only the analyses best suited to your model (and again, consider adjusting your priors in favor of learning Bayesian statistics).  (Source) 9. Get your story straight. What’s the story that your model is telling? Being explicit about this will help you identify which parts of the model are essential and which are unnecessary. It also helps when you want to communicate features of your model to other academics. This principle is especially true when it comes to the less intuitive mathematical or computational aspects of the model. Understanding the model’s overall goal helps with interpreting its individual parts. 10. Be open. Clearly describe how and why your model is constructed so that others can understand it, replicate it, and attempt to use it in other research applications. Being vague doesn’t do anyone any favors. Smaldino recommends trying the ODD protocol of model description: Overview (The model’s “story”), Design (A description of the model’s algorithmic mechanics), and Details (All the finer details of the algorithm). Also, be a cool person and open-source your code by documenting it on a code repository like GitHub. That way, if anyone wants to reference the inner workings of your model, switch out its individual parts, or build on top of it, they can easily do so. Open science is good science. -------------------------------------------------------------------- V Lessons for Modeling Collaborations Every serious researcher should learn to engage with the modeling literature of their field. Modeling is some of the most important work of any science, so you should understand and be able to learn from the models in your field even if you don’t produce models yourself. There are plenty of opportunities for empirical researchers to collaborate with modelers, but there are also many pitfalls involved in such collaborations. As a modeler, you need to respect the expertise of empirical researchers, who have often dedicated years to studying their subdomains. The researcher needs your help to fully understand the mechanics of the model, so that they can make their contributions as necessary. To do this, you need to teach them how the model works. As a researcher, you need to respect the expertise of the modelers and to help them construct and refine their models by walking them through the intimate details of the theory. To best do this, you need to understand how the model is being constructed. In other words: As a modeler, it’s your job to learn the theory. As a researcher, it’s your job to understand the model. And as collaborators, it’s everyone’s job to teach one another and to develop a mutual understanding and respect for the domains of the others. Only then can you properly work together to construct a theoretically sound model. ------------------------------------------------------------------- VI Conclusion The best advice to start model making is to just jump right in. Keep at it until you can get the fundamentals down. Recognize that no model will be perfect, and that complex theories will often require a family of models to accurately represent them. Your model’s failures can teach you as much about a subject as its successes. Now get out there and do some science! Unless you’ve decided to switch to model trains instead. Then go do that.  Glossary
I figured it would be good to define some of the terms used heavily in the article. But feel free to skip this if you’re a scoundrel. --------------------------------------------------------------------------------
Written by Sam LevineCSUF grad, research assistant, & professional dilettante. https://twitter.com/OstensiblyHuman
2 Comments
Willem Frankenhuis
12/2/2020 10:53:53 am
Great post! I wish the website would allow me to expert to PDF, so I could store in that format and share with colleagues?
Sam Levine
12/2/2020 06:37:30 pm
Unfortunately Weebly doesn't support this function, but I went ahead and made a PDF version for you. :) Leave a Reply. |

{kind=link}